
Regions and Availability Zones
Even better than tape backup

It was a while ago, to be sure, but I remember the day ever so clearly. One of my customers had a failure. The accounting software had failed again, but not to worry—they had a good backup. Could I help restore it?
They handed over the tape, telling me it was “the good tape: we've never had a problem with it.” It looked like a terrific tape; the aluminum case was nice and shiny.

The backup on the tape was secure and very safe. However, despite many attempts, nobody was going to be able to read it. It sounded great, though.
In the early days of computer networking with accounting workstations, the concept of high availability, failover, or durability was not a daily consideration for many companies. Backups were a task assigned to the newest office employee.
Today, people still assume that systems are not going to fail … and then they fail.
The concept of rotating backup tapes every other day or performing multiple backups with different tapes every day, one after the other, had not been implemented.
Moving a situation to today's cloud world, how does this story hold up?
Operating in the cloud, it's the customer's responsibility to back up their data. That’s part of each customer's implicit agreement with AWS: Security in the cloud is still the customer’s responsibility.
If a customer has an application running in the cloud, such as an accounting application, the cloud provider's responsibility is to ensure that the underlying hardware resources, i.e., the bare metal servers hosting the virtual servers and the storage tiers or database servers with attached virtual hard drives, remain powered up and running.
There are always many moving parts under the hood to consider, which brings us to the practice of designing with high availability and failover.
Operating in a cloud environment mandates that you understand the underlying infrastructure components and how to design your application to always be available.
Let's explore the concepts of high availability and failover when hosting and running applications in the AWS cloud.
Over 36 Regions and Counting
At AWS all online cloud services are hosted in geographical locations called regions, which are steadily expanding in number. Regions are sub-grouped into North America, South America, Europe, the Middle East, Africa, Asia Pacific, Australia, and New Zealand.
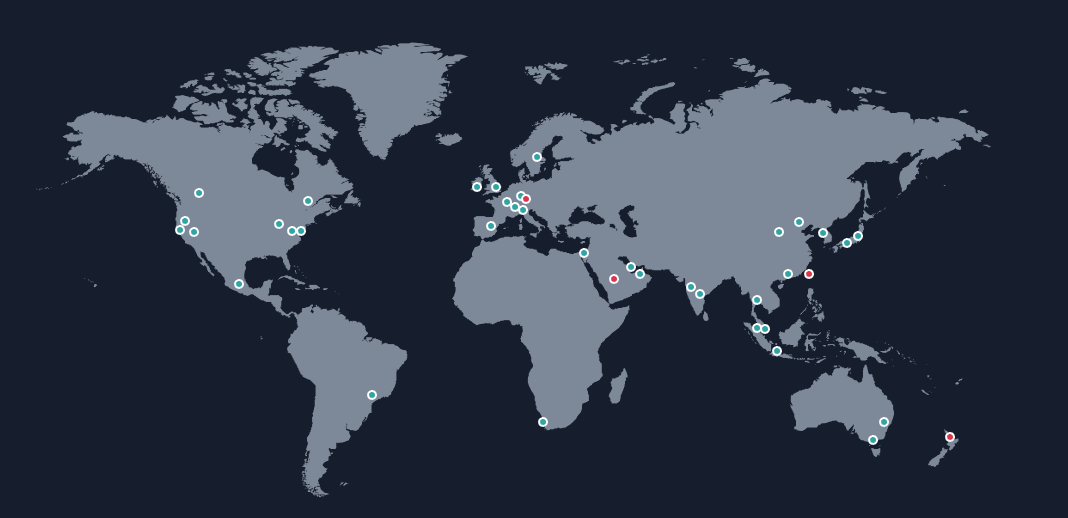
AWS Fault Isolation Boundaries
Each region consists of at least three areas called availability zones, or AZs for short. Northern Virginia is the biggest region with six availability zones.
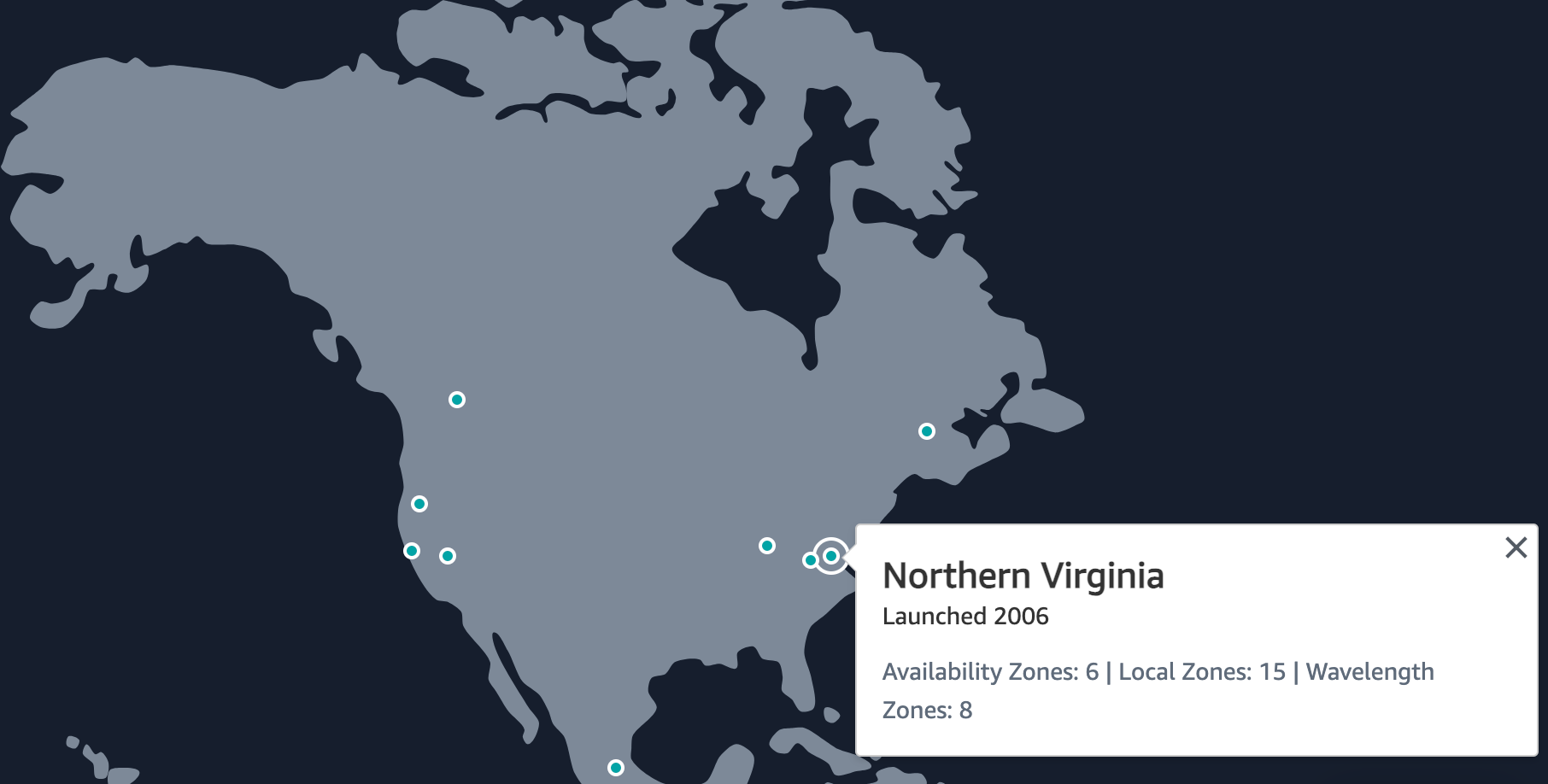
Tokyo and Seoul regions have four availability zones, and every other region has a minimum of three.
Understanding Regions and Availability Zones
Regions and Availability Zones in AWS are essential to understand because, surprisingly, not all cloud infrastructure is magically floating in a single, omnipotent server farm tended by AI bots.
Each availability zone (AZ) has at least one data center (DC) dedicated to hosting customer workloads. Multiple DCs per availability zone are dedicated to hosting customer workloads; however, the exact number is not shared with the public.
Each availability zone is an isolated cluster of data centers within each AWS region. Each AZ also operates with its own independent power, cooling, and networking infrastructure, ensuring that it remains unaffected by failures in other AZs within the same region. Within each region, these zones are physically separated—often by significant distances—but are interconnected via high-speed, low-latency networks, allowing for efficient communication and data replication.
Why does this matter? Availability zones are close enough for low-latency connections but far enough apart to survive floods, earthquakes, or the occasional alien invasion—AWS calls this "high availability" and "fault tolerance," but you can think of it as "not putting all your eggs in one basket, genius."
This also ensures your precious cat meme website doesn’t crumble the moment a squirrel chews through a power line.
Using regions and multiple availability zones lets you architect systems that don’t collapse at the first sign of trouble, which, let’s be honest, is a skill worth having in a world where downtime equals angry users and lost money.
Three Advantages Provided by Availability Zones
High Availability: With multiple availability zones in each region, your application can keep running even if one zone gets hit by a blackout, a rogue flood, or a motivated hacker. Data and workloads can failover to another zone faster than you can say "uptime SLA."
Fault Tolerance: Regions and availability zones are designed to be isolated so a failure in one doesn’t cascade to others. Your application can be designed to stay online using the same practices that AWS follows to keep its cloud services up.
For example, RDS multi-AZ deployments can maintain standby replicas in separate AZs, enabling seamless failover if the primary database instance fails. At a minimum, how most RDS database engines are designed to be deployed in production by default is a real-world best practice example of basic high availability and fault tolerance that AWS does very well.
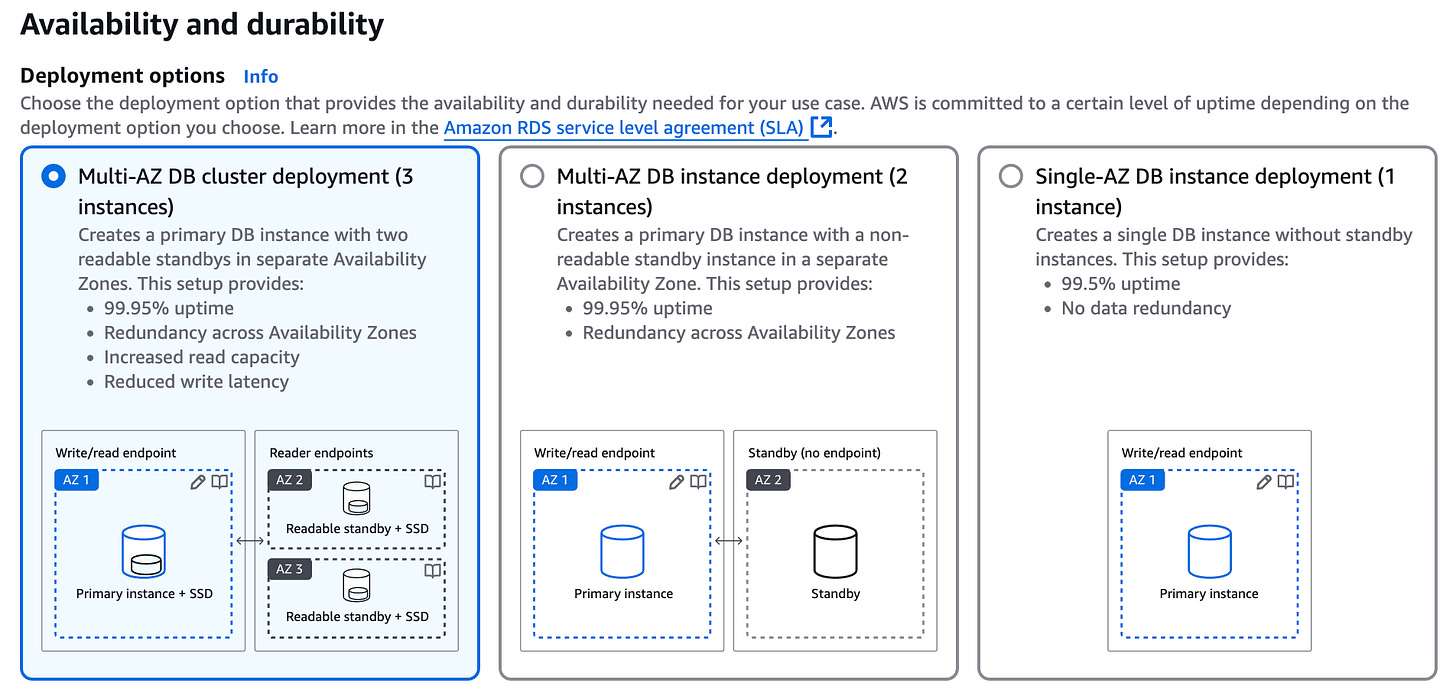
AWS RDS PostgreSQL deployment options Disaster Recovery: Spread your data across separate regions, and you’ve got a Plan B when a hurricane, earthquake, or Godzilla flattens a data centre. Multi-region setups mean your backups also have backups, and you’re not left performing last rites over a dead server rack.
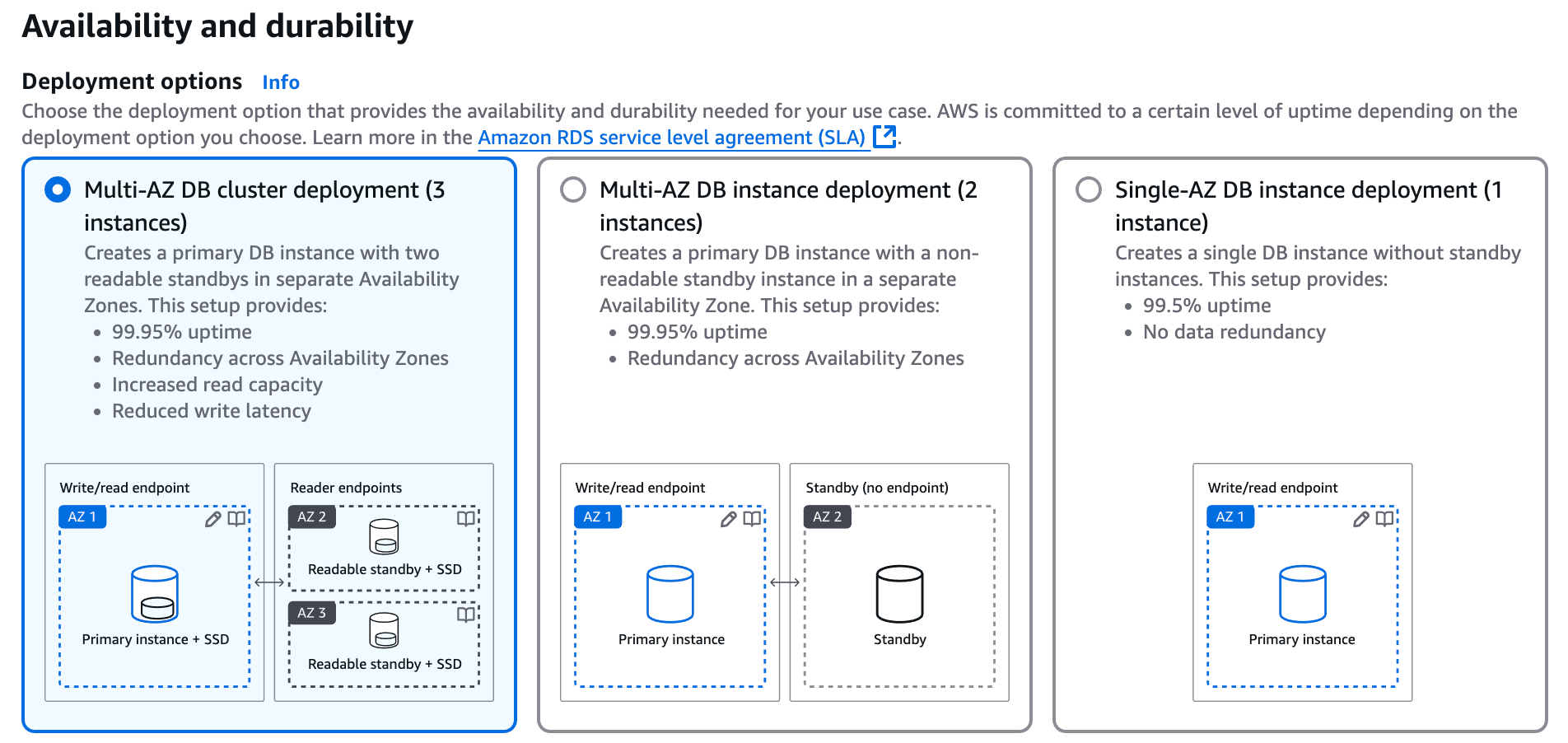
PostgreSQL Example
Deploying PostgreSQL on Amazon RDS offers several key advantages in terms of high availability (HA), fault tolerance, and disaster recovery. Below, I outline how RDS enhances each of these advantages.
Amazon RDS enhances PostgreSQL deployments by providing Multi-AZ deployments for high availability and fault tolerance and automated backups, snapshots, and cross-region replication for disaster recovery, all underpinned by AWS’s managed infrastructure.
High Availability
Designed Using Multi-AZ Deployments: RDS provides a feature called Multi-AZ (Multi-Availability Zone) deployments for PostgreSQL. This setup creates a primary database instance in one availability zone and one or more synchronous standby replicas in different availability zones within the same region. Availability zones are designed as isolated locations designed to be independent of failures in other zones.
Automatic Failover: If the primary DB instance experiences a failure due to hardware issues or network disruptions, RDS monitoring automatically detects the issue and fails over to a standby instance. The selected standby DB then becomes the new primary, minimizing downtime and ensuring the database remains accessible to the application and clients.
Benefits of Multiple Availability Zone Design: This configuration enhances high availability by reducing the impact of infrastructure failures, keeping the database operational with minimal interruption.
Fault Tolerance
Multi-AZ Resilience: The same Multi-AZ setup that supports high availability also contributes to fault tolerance. By maintaining a standby instance or two that are kept in sync with the primary via synchronous replication, RDS ensures the database tier can continue operating even if the primary instance encounters a fault.
AWS Managed Infrastructure: AWS manages the security of the cloud. Therefore, the underlying managed hardware performs software patching and handles routine maintenance tasks. This reduces the likelihood of faults caused by hardware failures or outdated software, enhancing overall system reliability.
Automated Failover: The automatic failover mechanism eliminates the need for manual intervention during a fault, allowing the database to tolerate issues seamlessly and maintain functionality.
Disaster Recovery
Automated Backups: RDS provides automated backups that capture the entire database instance and its transaction logs. These backups enable point-in-time recovery, allowing you to restore the database to a specific moment within the backup retention period (configurable up to 35 days).
Database Snapshots of EBS Storage: Automated snapshots of the database data records are stored durably in Amazon S3 object storage. Snapshots are used to restore the database after a catastrophic event.
Cross-Region Read Replica Options: RDS supports the creation of read replicas running on a separate EC2 instance in different AWS regions using PostgreSQL’s logical replication. In the event of a regional disaster, a cross-region read replica can be promoted to a standalone primary database, providing geographical redundancy and a recovery path.
Benefits: Together, these features offer robust disaster recovery capabilities, ensuring data durability and the ability to recover from major failures across different scales.
These benefits are why smart architects spend hours analyzing region and zone placement instead of just crossing their fingers and hoping for the best.
The architect’s job is to translate business needs—uptime, speed, compliance, budget—into a cloud design. Regions and AZs are how they make it happen, balancing trade-offs like cost versus redundancy or latency versus data rules. Without them, you’re just guessing where stuff runs, and that’s a recipe for outages or angry regulators. For something like the SAA-C03 exam, this is bread-and-butter knowledge—expect questions on multi-AZ designs or multiple region deployments for specific scenarios.
No backup tapes required!